One long pending issue clients reported was the slow overall recovery time for Ceph clusters to be back at HEALTH_OK status. Depending on the actual hardware and setups (mainly the number of disks), this duration was reported to vary from one to multiple hours when there were power failures or planned maintenance. We’ve acknowledged this ticket and were able to reproduce it. After some observations, we could conclude that an action as simple as restarting ceph-osd (Object Storage Daemon) could lead to such a long recovery process.
As an example of a 3 node cluster, I restarted all ceph-osd in the first node.
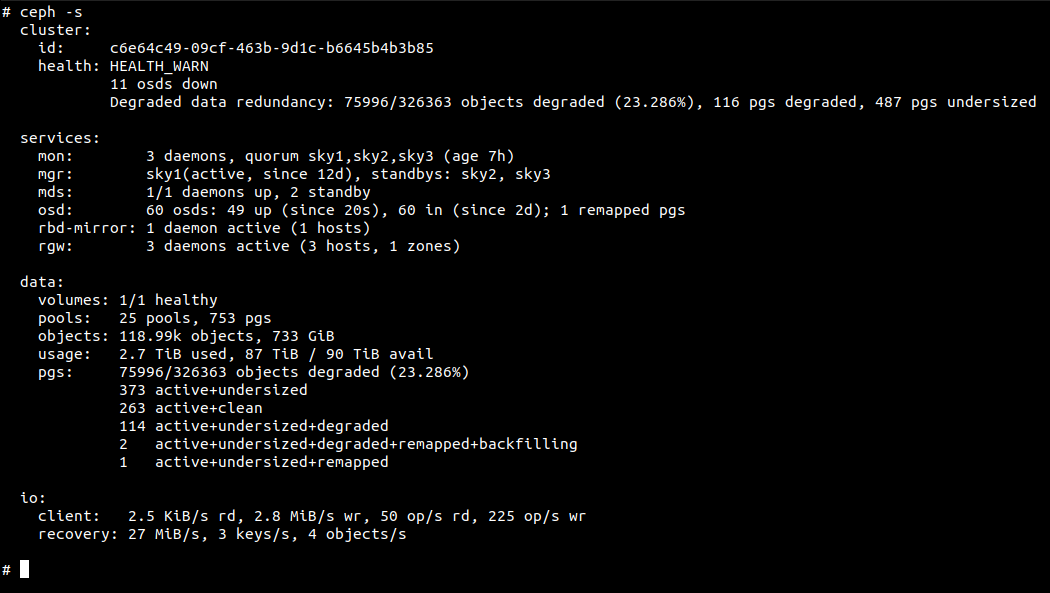 Image Source : Bigstack CubeOS
Image Source : Bigstack CubeOS
10 minutes later I still had the above HEALTH_WARN status. It complained that 14 osds were down and pgs were undersized. The warning made sense as this storage cluster was configured to have 3 replications with host as the failure domain. When osds on one node out of three were down, ceph was not able to complete the third replica, resulting in undersized pgs. The problem would be aggravated when it’s a bigger cluster with mode nodes, where ceph would start to peer and make the third copies on another node. This would be a complete waste of disk I/Os because as soon as those 14 osds were back to up condition ceph would realize that there are 4 copies and then do more work to delete the extra copy. These unnecessary disk activities not only shortened disk lifespan, especially SSD, but also added memory usage to osd processes. Those were not all of it. Be noted that this is a running cluster, ceph was still serving storage requests. Ceph would continue to write data and distribute the pgs to remaining osds. The implied that once those 14 osds rejoin the cluster, they had to sync-up and rebalance pgs again. It’s getting clear that the sooner osds could resume to up state, the better it is for the overall storage cluster in every way.
To get a closer look at the logs, I stopped one of the osd processes that took a long time to boot and manually ran it with debugging flags.
# systemctl restart ceph-osd@7
# /usr/bin/ceph-osd -d --cluster ceph --id 7 --setuser ceph --setgroup ceph --debug_bluefs 10 --debug_bluestore 10
There was a plethora of messages but in general things looked fine until
bluestore(/var/lib/ceph/osd/ceph-7) _open_db_and_around read-only:0 repair:0
And after this step there were an overwhelming number of read activities to rocksdb. This was confirmed from iostat of the disk. After a bunch of googling and headless experiments, I have observed that some osds seemed to come back up faster than others. The hints pointed to excessive reading in bluestore rocksdb. So what was the biggest data that was stored there?
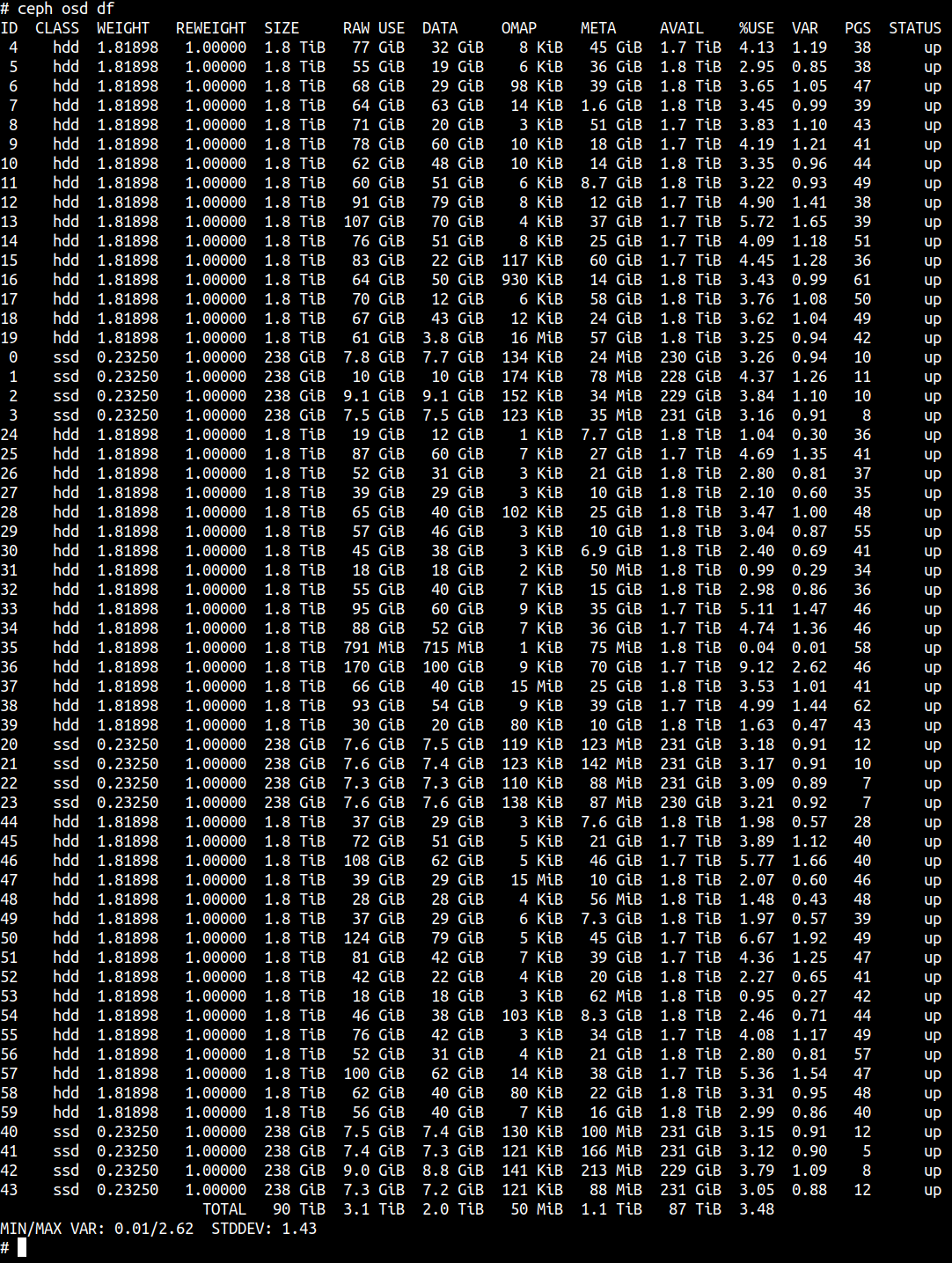 Image Source : Bigstack CubeOS
Image Source : Bigstack CubeOS
When we checked ceph disk free, one column that looked suspicious was META. Some of the osds were relatively small in size (MB) while most others were in GB. It turned out that the bigger META size it was, the longer it took for osd to finish booting. It matched what we observed in that META resides in bluestore rocksdb.
Fortunately, ceph comes with a tool to reduce the META data.
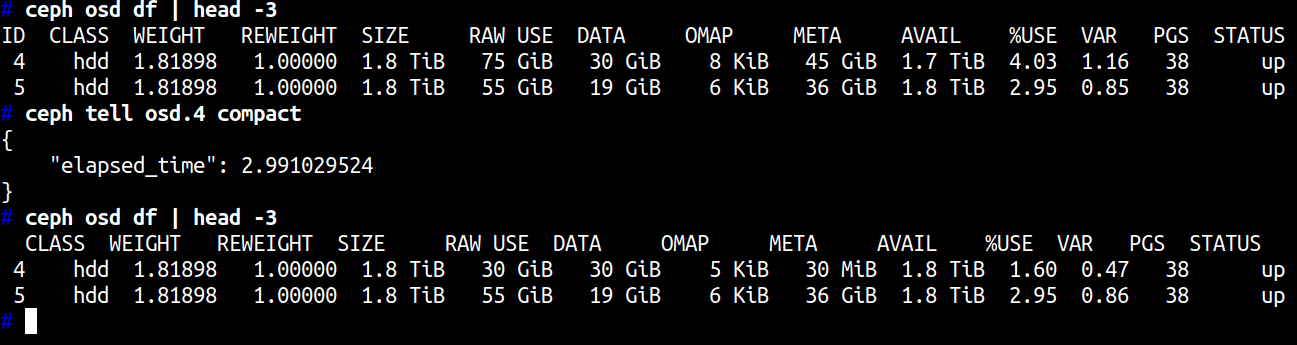 Image Source : Bigstack CubeOS
Image Source : Bigstack CubeOS
And that’s all! After META was compacted and size reduced to few dozen megabytes. The osd was able to complete booting and be recognized as up in seconds.
By adding this simple step in our scripts, we could from this moment on restart each osd without concerns to impact performance and introduce recovery overheads. This was a significant improvement that largely reduced support and maintenance costs as well as client experience.

