When Linux kernel panics, we, as an OS provider, are next to panicking too. It’s an automatic trigger for the team to put down everything else, jump right down into the water and fix it. If the fix does not show up, disasters will.
When the operating system fails to boot, the options left are limited. There is no running system to execute commands or run diagnostic tools and no operable console to view logs not to mention internet connection for remote access. This is one moment when old-fashioned serial consoles come handy. On high-end servers, there are generally BMC/IPMI, acting as out-of-band channels, for you to access control systems and interact with the target machine via serial connections. If you don’t have the luxury, network accessible IP-VGA or D.I.Y. style console server (with 1-to-many RS232 interfaces) can serve the same purpose. As a last resort, you have to be present on site in front of the KVM monitor with a hope that clients are not nearby staring at you.
In most kernel panic cases I’ve encountered, they had to do with drivers, especially drivers for filesystems. Linux root (/) folder and its subfolders and files reside in a filesystem which is generally a formatted partition in a disk drive. When the power button is pressed, BIOS/UEFI is booted and based on its boot order attempts to load and execute the OS. In order to recognize the file system the running system needs to load needed drivers. The running system is usually initramfs that is small enough to be loaded into memory and acts as a temporary operating system.
When initramfs can be successfully executed, things are not as bad. At least we can still enter various stages of bootstrap by appending or modifying linux kernel parameters. The idea works like Linux runlevels, allowing us to investigate which step goes wrong. These are my checkpoints:
- Are drivers missing?
- Are paths correct?
- Are drivers loaded?
- Are hard drives detected?
- Are file systems recognized?
- Are folders mounted and contain contents?
- Are environmental variables with required values?
- Is switchroot successful?
We can walk through a concrete example some other time but today I am dealing with a case when the above tips don’t work.
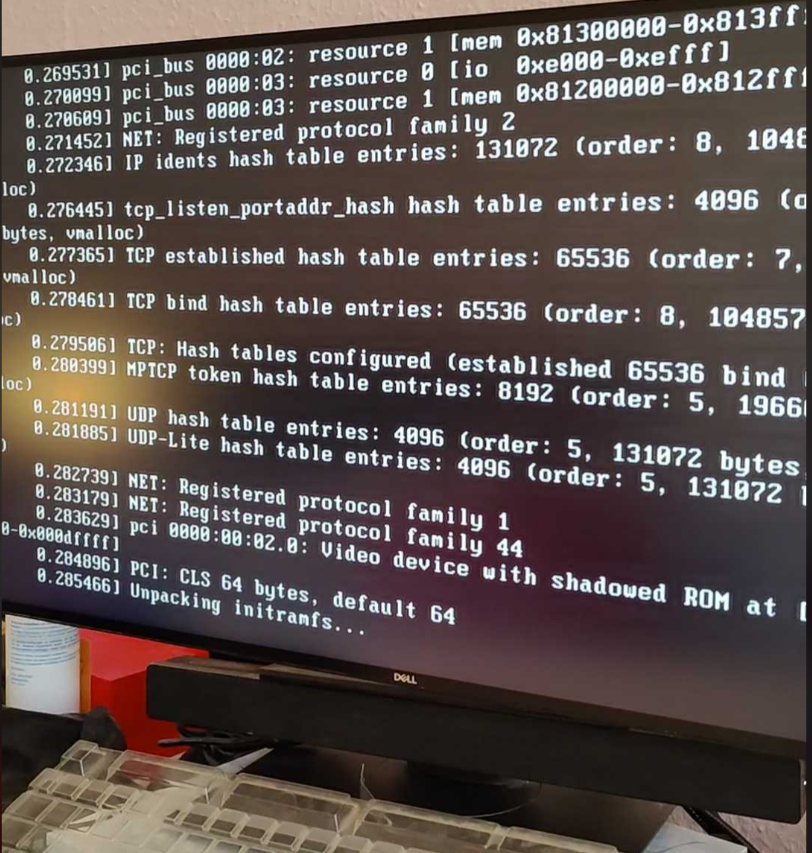 Image Source : Bigstack CubeOS
Image Source : Bigstack CubeOS
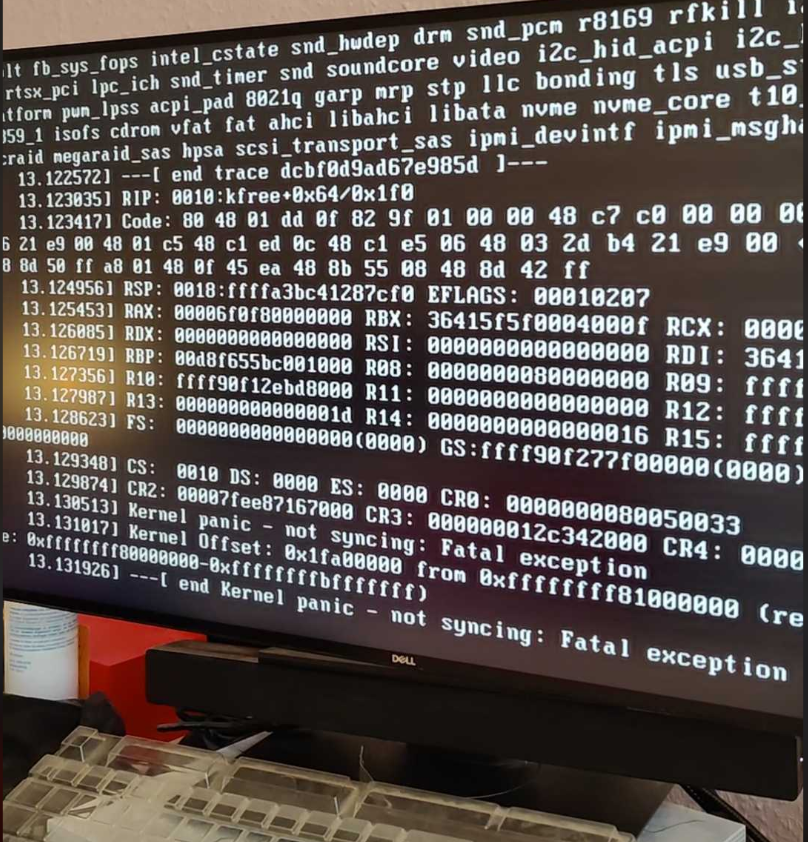 Image Source : Bigstack CubeOS
Image Source : Bigstack CubeOS
Soon after initramfs was unpacked, kernel died. It listed the drivers that matched what I incorporated in the initramfs but it didn’t tell why it panicked. At least I could not understand.
I fiddled with some linux boot parameters, initramfs_size, acpi, etc. with no luck. Then I ruled out the possibility of bad memory, bad drives, motherboard because the existing OS still worked. Fortunately with our CI/CD pipeline, we can be sure that the last-released firmware still worked. Therefore, I checked the difference of changesets from the time of last known good build till today but still found nothing noticeable. Finally by opening up the packaged firmware and making some comparisons I could see the kernel versions were slightly different: kernel-4.18.0-348 versus kernel-4.18.0-373 Through the build process, we relied on rpm package manager to based on provided repositories, resolve dependencies and install packages. This has multiple advantages, letting us keep up with the latest and greatest packages as well as saving the source code repo. space and effort of maintaining our own rpm repositories. On the contrary, it makes our life harder when it comes to applying patches, hotfixes or fixpackes on deployed systems on client sites. Every new build is potentially different and in this case it was the small difference that led to kernel panic during firmware installation.
After finding out the culprit, I decided to lock kernel packages which are too critical to be out of control.
sh-4.4# dnf install -y 'dnf-command(versionlock)'
sh-4.4# dnf -y install kernel-core-4.18.0-348.el8.x86_64 kernel-modules-4.18.0-348.el8.x86_64 kernel-headers-4.18.0-348.el8.x86_64 kernel-4.18.0-348.el8.x86_64 kernel-modules-extra-4.18.0-348.el8.x86_64
sh-4.4# dnf list installed | grep kernel | tr -s ' '
kernel.x86_64 4.18.0-348.el8 @baseos
kernel-core.x86_64 4.18.0-348.el8 @baseos
kernel-headers.x86_64 4.18.0-348.el8 @baseos
kernel-modules.x86_64 4.18.0-348.el8 @baseos
kernel-modules-extra.x86_64 4.18.0-348.el8 @baseos
Add the kernel packages to lock list with “dnf versionlock add”
sh-4.4# dnf versionlock list
Last metadata expiration check: 0:28:02 ago on Thu 21 Apr 2022 06:06:00 PM CEST.
kernel-0:4.18.0-348.el8.*
kernel-core-0:4.18.0-348.el8.*
kernel-modules-0:4.18.0-348.el8.*
kernel-modules-extra-0:4.18.0-348.el8.*
kernel-headers-0:4.18.0-348.el8.*
ship$ sudo dd if=CUBE_2.2.4_20220421-1616_55765df7.img of=/dev/sda bs=4M
1459+1 records in
1459+1 records out
6122962944 bytes (6.1 GB, 5.7 GiB) copied, 505.694 s, 12.1 MB/s
Then come these 2 major packages that give us daemon, rados-ng/rados-kv and config files
sh-4.4# dnf -y install nfs-ganesha-ceph.x86_64 nfs-ganesha-rados-grace
Now insert the USB that contains our newly-built firmware and power-cycle our NUC to boot off the USB drive, we could pass the panic point and successfully complete the boot process.
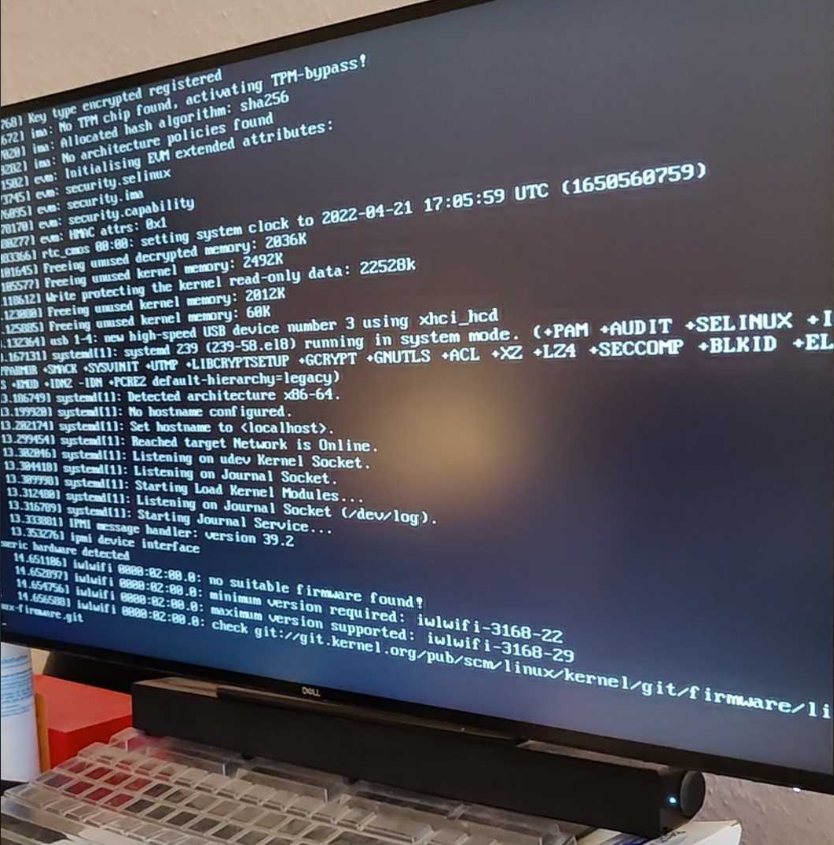 Image Source : Bigstack CubeOS
Image Source : Bigstack CubeOS

